ASLR & the iOS Kernel — How virtual address spaces are randomised

In this blog post I want to take a look at ASLR and how the iOS kernel implements it for user-space processes.
We’ll cover:
- what ASLR actually is and how it aims to mitigate exploitation
- how the iOS kernel implements ASLR for apps & processes that are executed on the device
- a short experiment you can try that involves patching the iOS kernel to disable ASLR across all user-space processes!
What is ASLR?
ASLR stands for ‘Address Space Layout Randomisation’ — it is a security mitigation found in pretty much all systems today.
It aims to make it difficult for an exploit developer to locate specific parts of a program in memory by randomising the memory address space of the program each time it is launched.
This results in the exploit developer not being able to predict the memory location of variables and functions within their target, adding a layer of difficulty to common exploit techniques like Return Oriented Programming.
The way ASLR implements this randomisation is by sliding the entire process address space by a given amount. This given amount is known as the ‘slide’ or the ‘offset’.
The following diagram aims to illustrate how a process without ASLR compares to a process with ASLR.

Looking at the diagram, Process A is loaded into memory at a static virtual address — 0x10000. Process A will always be loaded into memory starting at the same base address due to the lack of ASLR. This means that an attacker can easily predict where specific variables and functions will be in memory.
Process B, on the other hand, is loaded into memory at starting at base address 0x14c00. This base address is dynamically calculated — every time Process B is launched, a slide value is generated at random and added to the static base address.
In the diagram the random slide value used is 0x4c00. This value is added to the static base address — 0x10000 — which results in a new, randomised, base address.
0x10000 + 0x4c00 = 0x14c00
Every time Process B is launched, a new slide value will be chosen at random and therefore the base address (and the address of everything else in the binary) will be different each time.
Unlike with Process A, an attacker cannot easily determine where in memory specific variables and functions will be located in Process B. This is the goal of ASLR.
Note that the entire address space is shifted by the slide amount, resulting in variables and functions still being located at the same relative position to each other. This means that if the memory location of a single variable or function can be leaked, the address of everything else in the process can easily be calculated, thus defeating ASLR altogether.
Exploit developers often rely on an information leak vulnerability — a bug that leaks a pointer from the target process — in order to defeat ASLR using this method.
ASLR on iOS
On iOS (and on most other operating systems) ASLR is implemented for both the kernel and the user-land processes.
The kernel’s ASLR slide is randomised on every reboot. The slide value is generated by iBoot, the second stage boot-loader, during the boot process.
For user-land processes, the ASLR slide is randomised every time a process is executed. Every user-space process has a unique slide. The slide value is generated by the kernel during the binary loading routine.
In this blog post we will be focusing only on the user-land ASLR in iOS, and more specifically how the kernel implements it.
The iOS kernel is based on XNU, and XNU is open source. This makes it fairly easy to look into how parts of the iOS kernel work as we can refer directly to the source code.
The iOS kernel isn’t a direct result of compiling XNU however. Apple adds new, iOS-specific, code to XNU and these parts are kept closed source, although referring to the XNU source code is generally still very useful for getting a high-level understanding of parts of the iOS kernel code base.
The function load_machfile() in bsd/kern/mach_loader.c in XNU is responsible for parsing a given Mach-O file (the executable format used on iOS) and setting up a new task, loading it into memory etc. Every time you open an app or run a binary on your iPhone, this function is called in the kernel.
It’s in this function that the ASLR slide for the new process is generated.
In load_machfile(), after the initial setup of creating a new pmap and vm_map for the to-be process, we reach the code responsible for generating the ASLR slide.

There’s actually two ASLR slide values being generated here — one for the new process and one for dyld. Both are generated in the same way.
Firstly, a random 32-bit value is generated by the call to random().
Secondly, this random value is ‘trimmed’ down so that it does not exceed the maximum slide value. On 32-bit, this value gets trimmed down to just one byte. On 64-bit it’s two.
Thirdly, the trimmed value is shifted left by an amount depending on the host’s page size.
The resulting value is the ASLR slide.
For example:
random()returns0x3910fb29
2. Value 0x3910fb29 is trimmed down to 0x29(assuming 32-bit OS)
3. Byte 0x29 is shifted left by 0x12 (the page shift amount)
The resulting 0x29000 is the ASLR slide value that will be used for this new process.
Shortly after the slide values are generated, load_machfile() calls into another function — parse_machfile(). This function is much larger and proceeds to load each Mach-O segment into the virtual memory space, perform code-signing-related tasks and ultimately launch the new process.
To see ASLR in effect, compile the following program on your iOS device.
#include <stdio.h>
#include <string.h>char *str = "HELLO ASLR";int main() { printf("ptr %p\n", str); return 0;
}
This code prints a pointer (using the %p format specifier) to a static char array stored in the binary.
Compile this code using the -fpie flag. This flag enables the code to be ‘position independent’ — essentially meaning it supports address space randomisation.
This should actually be enabled automatically and, in fact, 64-bit iOS enforces it. If you’ve ever dealt with ASLR on 64-bit iOS, you may have noticed that compiling a binary with -fno-pie (to disable position independent code) has no effect — all processes are launched with ASLR regardless.
If you run the above program a few times, you’ll notice that the pointer to the static char array changes on each new execution. This is due to a new slide value being generated by the kernel each time.
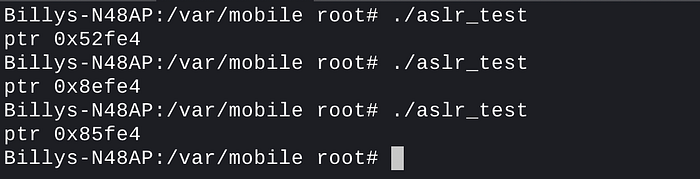
You may also notice that the three right-most hexadecimal digits remain the same — this makes sense as we know from the kernel code that the format of the slide value will always be 0xXX000.
Patching the iOS kernel
A nice experiment you can try given the knowledge above is to actually patch the iOS kernel so that ASLR is disabled system wide.
This is fairly straightforward to do — only a single instruction needs to be changed in the kernel in order for the ASLR slide to always be set to 0x0.
With a patch like this applied, all apps and processes executed (even those compiled with -fpie) will be mapped into memory at their static binary mapping.
This can even be potentially useful for other debugging/reversing tasks on iOS — having ASLR disabled at the kernel level can save you time having to recompile programs with the -fno-pie flag, or having to modify AppStore apps in order to run them without ASLR.
Unfortunately, due to KPP/KTRR on 64-bit iOS preventing us from writing to the __TEXT segment (the code section) of the kernel, we’ll be limited to using a 32-bit jailbroken device for this exercise.
You could apply the same patch in a static 64-bit kernel cache and boot the custom kernel on a device using an exploit like checkm8. But in this blog I’ll stick to patching it dynamically on 32-bit iOS 9.0 on my iPhone 5C.
Yeah, I guess 32-bit iOS is a bit redundant these days, but oh well. It’s still a cool little experiment to try out.
The first step is to locate the load_machfile() function in the iOS kernel for your chosen device.
Unfortunately the symbol for this function isn’t available in the RELEASE kernels so I had to locate it by searching for specific instruction patterns and using cross-references from other functions that do have symbols.
Locating the specific code is beyond the scope of this post, but if you’d like to see a similar reverse engineering task where I go into detail about locating a specific part of kernel code, check out my previous blog — https://medium.com/@bellis1000/exploring-the-ios-screen-frame-buffer-a-kernel-reversing-experiment-6cbf9847365
Here’s a snippet of the assembly code (taken from Ghidra) responsible for generating the ASLR slide.

This is from the same part of code in the load_machfile() function that we looked at previously. The same three steps used to generate the slide are handled here, although for the initial random value generation, read_random() is being called instead of random().
There’s quite a bit of flexibility here with how we go about applying a patch to this — we just need to set the slide value to 0x0, every time. That’s the aim. It doesn’t really matter how we do it.
You could:
- NOP-out this whole section of code so there’s no random generation at all
- patch
read_random()to always return 0x0, so the random number isn’t actually random - overwrite the random slide value with 0x0 right after it is generated
The method I‘m choosing is to patch the instruction bic r0, r1, 0x80000000. This instruction performs a bitwise AND operation on R1 and value 0x80000000. This is the last time the slide value (held in R0) is modified before it is passed to vm_map_page_shift().
If we can set the value to 0x0 just before the call to vm_map_page_shift() we will effectively disable ASLR. If the value is 0x0, shifting it by any amount — left or right — will still result in 0x0.
The ARM instruction bic r0, r1, 0x80000000 is represented by four bytes — 21 f0 00 40. This part of the kernel is actually in Thumb mode (making use of a combination of 16-bit and 32-bit instructions) so we must be careful to replace the instruction with the same amount of bytes to avoid messing up the alignment.
The instruction I want to replace it with is movs r0, 0x0 — this will reset the value of R0 to 0x0, thus overwriting the random bytes used for the slide.
However, this instruction is represented by only two bytes — 00 20— not four.
This isn’t really a problem though. All we need to do is replace the bic r0, r1, 0x80000000 instruction with two of the movs r0, 0x0 instructions so that we make up the amount of bytes.
So essentially:
bic r0, r1, 0x80000000becomes:
movs r0, 0x0
movs r0, 0x0The first time movs r0, 0x0 is executed, R0 will be set to zero. The second time it is executed nothing happens. It essentially acts as a NOP (no-operation) instruction. It does the exact same thing again, leaving no visible change in the register state.
I wrote a program that applies this patch to the kernel using vm_write() from the Mach API.
I have the instructions hard-coded — both the bic r0, r1, 0x80000000 and the two movs r0, 0x0 joined together.
#define DISABLE_BYTES 0x20002000 // movs r0, 0x0 x 2
#define ENABLE_BYTES 0x4000f021 // bic r0, r1, 0x80000000This allows me to easily disable and re-enable ASLR. All I have to do is patch the instruction with DISABLE_BYTES to disable ASLR, and un-patch the instruction by restoring the original bytes (using ENABLE_BYTES) to enable it again.
I also have the address of the target instruction.
#define INSTR_TO_PATCH_ADDR 0x802a3cc4This address is specific to the iOS 9.0 kernel for iPhone5,4. If you want to try this yourself, you’ll need the address of this same instruction but for whichever kernel and device you’re using.
The code then simply reads from the instruction address to determine whether or not ASLR is currently enabled or disabled, and then applies the patch by writing the opposite set of bytes to toggle it.
Below is the code for this program.
uint32_t slide = get_kernel_slide();
printf("[+] KASLR slide is %08x\n", slide); uint32_t current_bytes = do_kernel_read(INSTR_TO_PATCH_ADDR + slide); printf("[+] Current bytes %08x\n", current_bytes); if (current_bytes == ENABLE_BYTES) {
do_kernel_write(INSTR_TO_PATCH_ADDR + slide, DISABLE_BYTES);
printf("[+] Patched ASLR random instruction. ASLR disabled.\n");
} else {
do_kernel_write(INSTR_TO_PATCH_ADDR + slide, ENABLE_BYTES);
printf("[+] Patched ASLR random instruction. ASLR enabled again.\n");
}
Note: the functions get_kernel_slide(), do_kernel_read() & do_kernel_write() are all wrapper functions for Mach API calls that I have written. The code for these will be available on Github.
Now to see this code in action!
We’ll first run the test program a few times to verify that ASLR is enabled.

The addresses are randomised each time. Now we run the pwn_aslr program to patch the kernel code.

The bic r0, r1, 0x80000000 instruction has been patched and ASLR has been disabled. Now we re-run the test program to verify.
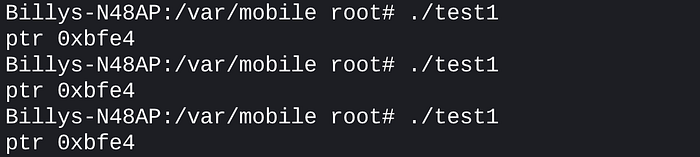
Now the addresses are static! The kernel patch worked and ASLR is no longer in effect.
Here’s a quick demo video showing the above in real time https://youtu.be/D_pnGfTMYUI.
The code for this tool is available on my Github if you want to explore it yourself. As I mentioned, you’ll need to find the address of the kernel instruction you want to patch for the specific device + kernel combination you’re using, unless you’re using iOS 9.0 on iPhone5,4.
You could also probably implement something similar on 64-bit if you use Luca Todesco’s KPP bypass or Brandon Azad’s A11 KTRR bypass.
Link to the code — https://github.com/Billy-Ellis/aslr-kernel-patch
Feedback always welcome. Thanks!
— Billy Ellis @bellis1000
